14.5 Variable Selection
After assembling the data, the next step is to parse down the parameters or features of each student down to the important features. You may start with many parameters, but given the rule mentioned above you do not want to build a logistic regression model with 1000 parameters unless you have 10,0000 data points.
So that being said, some selection needs to occur.
Step 1
If you are pooling data over multiple years are the predictors stable in direction and sign? If the predictor is not stable over time it may need to be removed from the model if you are predicting future years. For example if you find that the predictors are either not stable before a certain date, or predict opposite to the last few years of data, then remove them from your training data set.
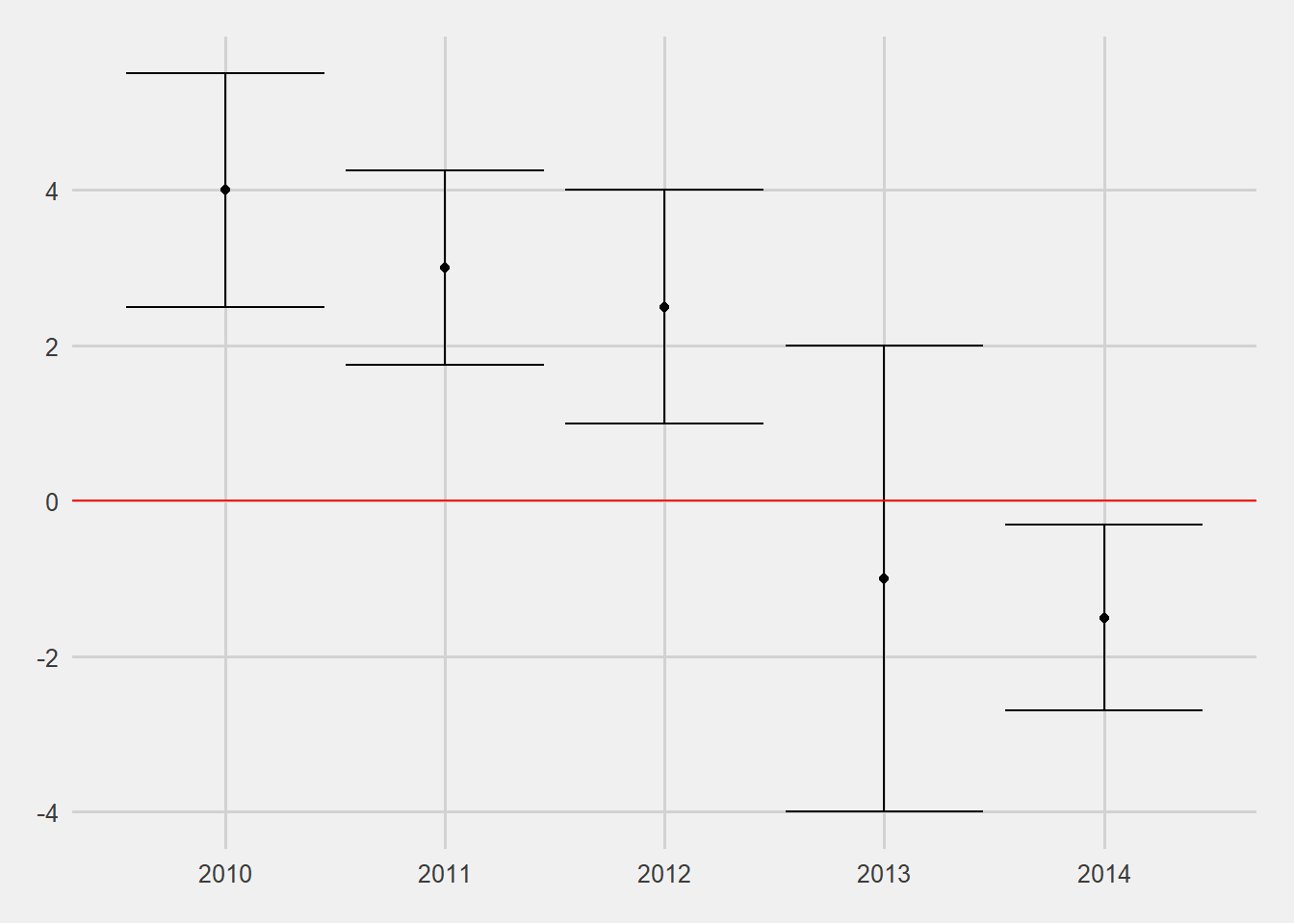
Figure 14.1: Consistency of Predictor Over Time Using Logistic Regression
Analysis has show that at Wake Forest most predictors have stabilized since 2013. Data from the 2010-2012 cohorts is drastically different than those from 2013 (in some cases a predictor in 2010 may be associated with improving retention while the same predictor for 2017 data shows that it is associated with a decrease in retention).
Step 2
Feature engineering can be used to create new predictors from the data that you currently have. For example you may have hours earned and attempted, but a better parameter may be the ration of hours earned/attempted. This kind of strategy is to take the data that you have and make it into parameters that may give more information or be more meaningful to the problem you are trying to solve.
Step 3
Now you can use some other algorithms to help to reduce the number of features. Some parameter reduction techniques include:
- Decision Trees – Explore the primary breaks in the tree to find the most important features.
- Random Forest – Look at the parameter importance metrics to see what the random forest indicates is most important.
- Principal Component Analysis – This technique reduces the features into composite features in order to explain the most variance in the fewest components. You can use this to see the parameters that were loaded into the features. Additionally, you can use the components themselves in the model.
- Penalised Regression (LASSO/ Ridge/ Elastic Net) – These regression techniques penalise addition of parameters. You feed the full model into the algorithm it shrinks the parameters (or in the case of LASSO reduces some to zero). These parameters can then be extracted as the “most important features”
Beyond the algorithm is it also important to talk to some of the data stewards and student facing persons. While the predictor may not be selected by the above algorithms, the literature may indicate that a predictor be included. For example race/ ethnicity might not be a good predictor by the definitions set in the above feature selection algorithms, but the Office of Academic Advising may say that in their campus interviews with students they find that a particular race group has a different set of concerns than another. Again, you have to use a human touch with some of the feature selection. This also helps to create buy-in from others on campus that you are considering their experiences in your modeling.